GLM-Free-API 服务已启动,请使用客户端进行连接
核心特性
流式输出
毫秒级首字节,边生成边传输,提升交互性能(SSE/Web/CLI)。
多轮对话
上下文记忆与压缩,保证长对话的稳定响应(Token 管理与截断策略)。
联网检索
实时信息聚合,提升回答的时效与准确性(可插拔 Provider)。
GLM 生态
深度集成智谱 AI 全家桶,支持 GLM-4 等先进模型。
接入指南
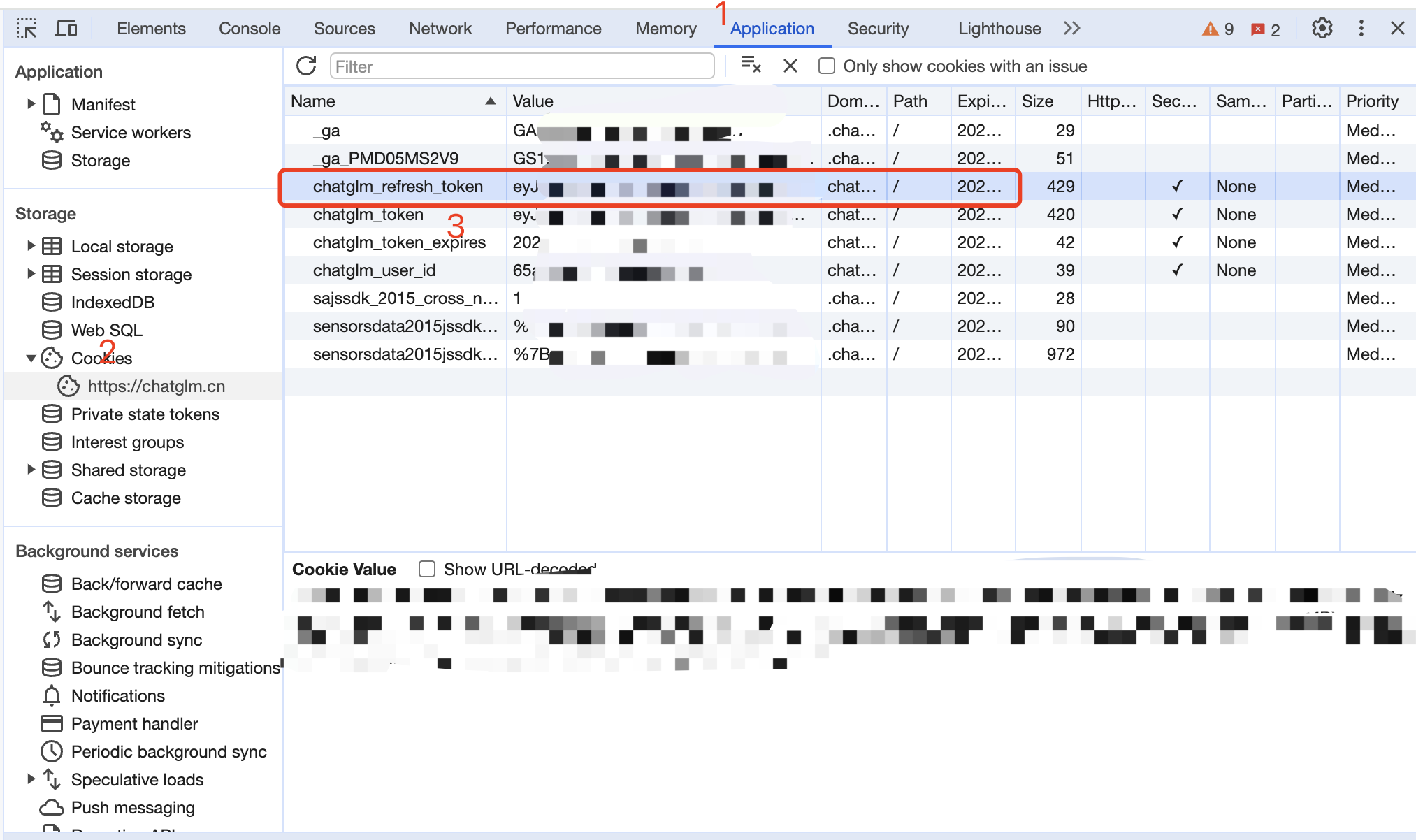
01 · 从智谱清言获取 Token
登录 智谱清言,随机发起一个对话,打开浏览器F12工具,在 Application › Cookies 中找到 chatglm_token。
Authorization: Bearer YOUR_CHATGLM_TOKEN
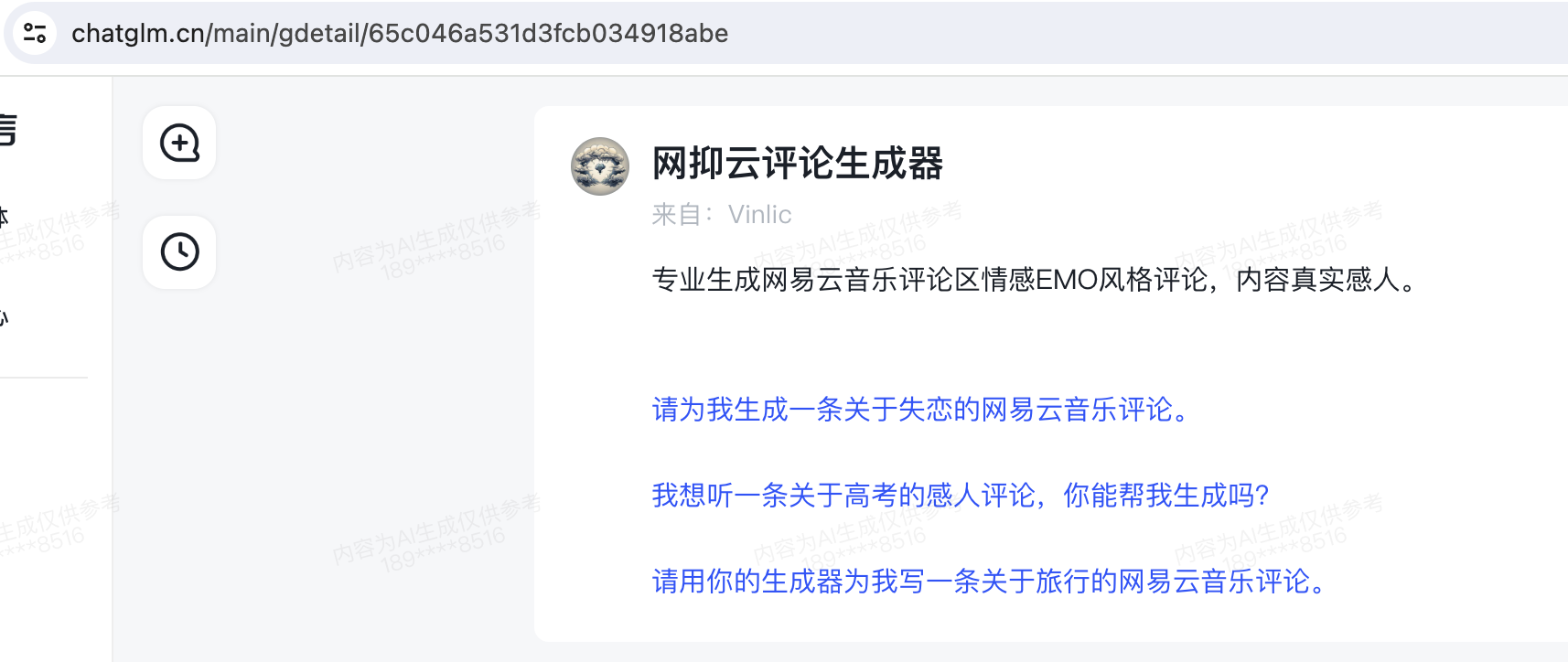
02 · 智能体接入(可选)
打开智能体的聊天界面,地址栏的一串ID就是智能体的ID,复制下来备用,这个值将用作调用时的 model 参数值。
03 · 多账号轮询
将多个 Token 用逗号拼接,服务自动挑选一个执行。
Authorization: Bearer TOKEN1,TOKEN2,TOKEN3
04 · 选择客户端或 SDK
推荐使用 LobeChat / NextChat / Dify 或直接使用 OpenAI SDK。
curl -X POST /v1/chat/completions \
-H "Authorization: Bearer YOUR_USER_TOKEN" \
-H "Content-Type: application/json" \
-d '{ "model":"glm-4", "messages":[{"role":"user","content":"Hello"}] }'
接口兼容性
OpenAI 兼容
/v1/chat/completions
推荐
Google Gemini 兼容
/v1beta/models/:model:generateContent
gemini-cli
Anthropic Claude 兼容
/v1/messages
claude-code
支持模型
GLM-4.7
高智能旗舰 - 通用对话、推理与智能体能力上实现全面升级 - 编程更强、更稳、审美更好
用途 · 高性能推理 / 编码 / 智能体
GLM-4.6v
超强性能 - 上下文提升至200K - 高级编码能力、强大推理以及工具调用能力
用途 · 高性能推理 / 编码 / 工具调用
GLM-4.6
超强性能 - 上下文提升至200K - 高级编码能力、强大推理以及工具调用能力
用途 · 高性能推理 / 编码 / 工具调用
客户端生态
覆盖聊天、命令行与应用开发场景。
LobeChat
现代化聊天界面。
NextChat
简洁多平台客户端。
Dify
AI 应用开发平台。
OpenAI SDK
直接编程接入。
ChatBox
桌面端聊天工具。
继续探索
更多客户端持续适配中。